CCDC Scoring Engine 2.0
Northeastern University competed in the Northeast Regional Collegiate Cyber Defense Competition a couple of weeks ago and I participated for my fourth year as the team’s captain. One major pain point in the competition in the past has been their ancient scoring engine - an old php project that runs on top of a LAMP stack. This year, they unveiled a brand new scoring engine designed around workers polling from a redis queue that store results in a backend database using SQLAlchemy with a front end web UI written with Flask. While their new engine may be more scalable, there were obvious issues with its implementation in the competition as it was periodically unavailable during competition hours and full of display layer bugs in the UI. I decided to take a stab at designing my own scoring engine for internal NUCCDC team use to see if I could do any better.
![]()
Scoring Engines are Hard
There have been a number of attempts to write scoring engines to serve the needs of the CCDC in the past by various authors over the years (projects by StrangeUSB, then3rd, and reedwilkins are some examples). I have even tried to write a scoring engine for NUCCDC team use. Unfortunately, all of these implementations suffer the same pitfalls when you consider their use in an actual competition environment: scalability and ease of use. And I get it, scalable applications are hard and take a lot of time and testing to develop. No one is looking to build a production quality system for CCDC competitions for free.
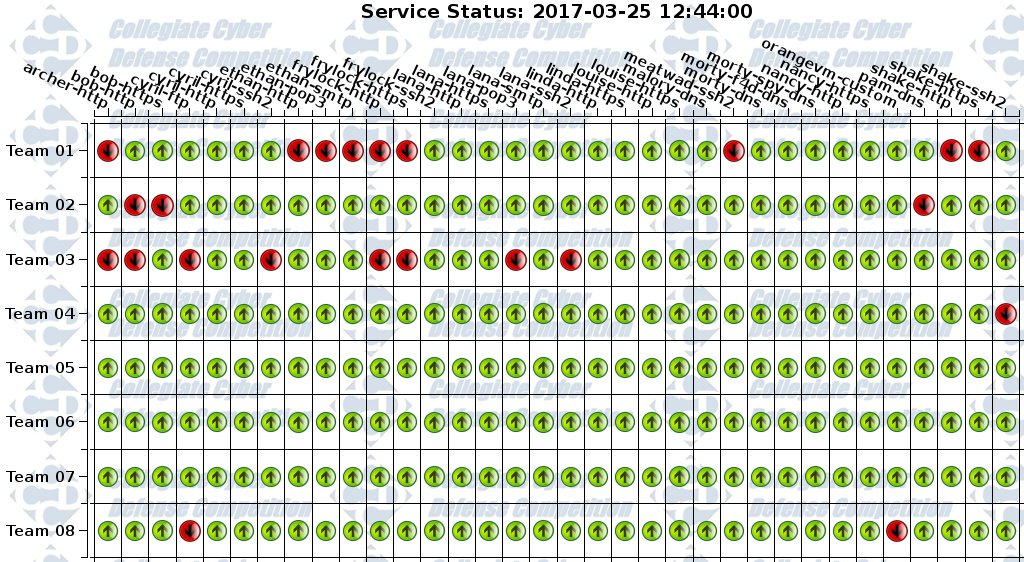
Scalability was, I think, the problem that the designers of this year’s NECCDC scoring engine were trying to solve and using a redis queue with workers running scoring tasks is a great way to do that. Unfortunately, they sacrificed support for some of the things the old scoring engine did well - injects (business related tasks assigned to the teams throughout the competition) had to be delivered on paper, by hand and submitted via email. We ended up losing a lot of points in the competition because, we realized later, we had a slight typo in the email address they gave us (or they gave us the wrong email) and a number of our submissions bounced.
Additionally, the scoring engine had to be disabled a couple of times during the competition for unknown reasons and suffered some pretty amateur display layer and caching issues. These issues combined to make the scoring engine almost useless to us - we couldn’t receive or submit injects, service status was frequently wrong due to caching issues, and the web UI often stopped working altogether, alerting a datatables javascript error. The competition infrastructure maintainers (the Black Team) assured us that this scoring engine outperformed previous engines and pointed to the sheer number of scored services as evidence, but I’m unconvinced that their project was ready to be used in an actual competition environment - it could have used another year’s development.
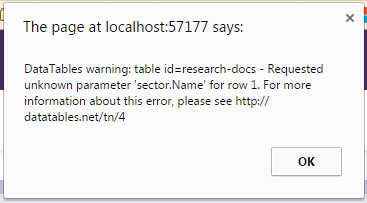
With a number of previous scoring engines available to learn from, the experience of developing an initial prototype myself, and the mistakes of this year’s NECCDC scoring engine in mind, I decided to take another shot at writing my own.
Building Something Better
Goals
I’d like to be able to take the good from previous scoring engines (inject viewing and submission, stability) and combine it with what this year’s engine did well (scalability, greater team control of scoring data - eg passwords and IPs). Here’s the list of eventual end goals:
- Scalability - use asynchronous workers to run scoring modules and be able to easily increase/decrease the number of workers.
- Stability - keep it simple, stupid, and validate everything.
- Team Control - teams should be able to control scoring engine relevant data without requesting changes from the White Team.
- Flexible Plugin System - new scoring modules should be easy to write and add.
- Feature Pairity - with previous implementations. This means an intuitive user interface, admin control, inject administration and submission, etc.
Design

Let’s start from the bottom and work our way up. Rather than writing my own task management on top of a redis queue I opted to go with a distributed task management system I’m a bit more familiar with: Celery. Celery is quick and easy to set up, scales well with multiple workers, and, best of all, allows us to develop plugins in pure python without having to worry about complex worker tasking and scheduling. You just need to have a message queue (I chose to use rabbitmq) for Celery to use. Writing a distributed task is as simple as adding a decorator to a python function:
from celery import shared_task
@shared_task
def score(service):
...You can then call this task asynchronously, letting Celery take care of all of the scheduling magic and worker management, with:
score.delay(service)Celery also integrates well with Django, my web framework and ORM of choice for this project.
I’ve got a lot of experience with Django from work and from my previous attempt at a scoring engine so it was only natural for me to use it here. For anyone unfamiliar, Django is a web application framework that includes templates and a database ORM. For this project, I’m using the Django REST Framework which allows me to create a REST API in parallel as I’m creating the front end web UI. Probably not entirely necessary for this project, but it might be a nice thing to have down the road. Some initial screenshots of the web view for the REST API:
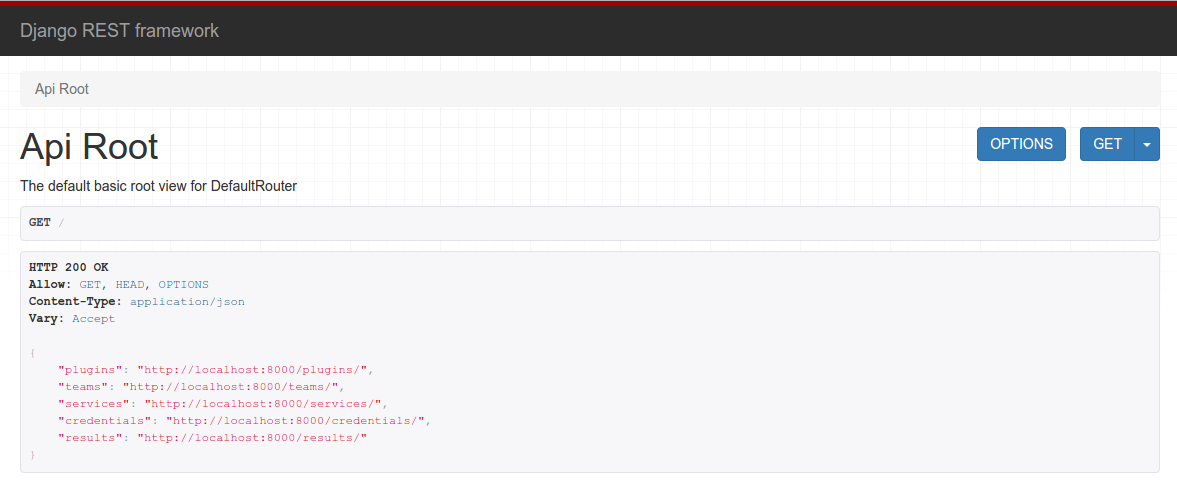
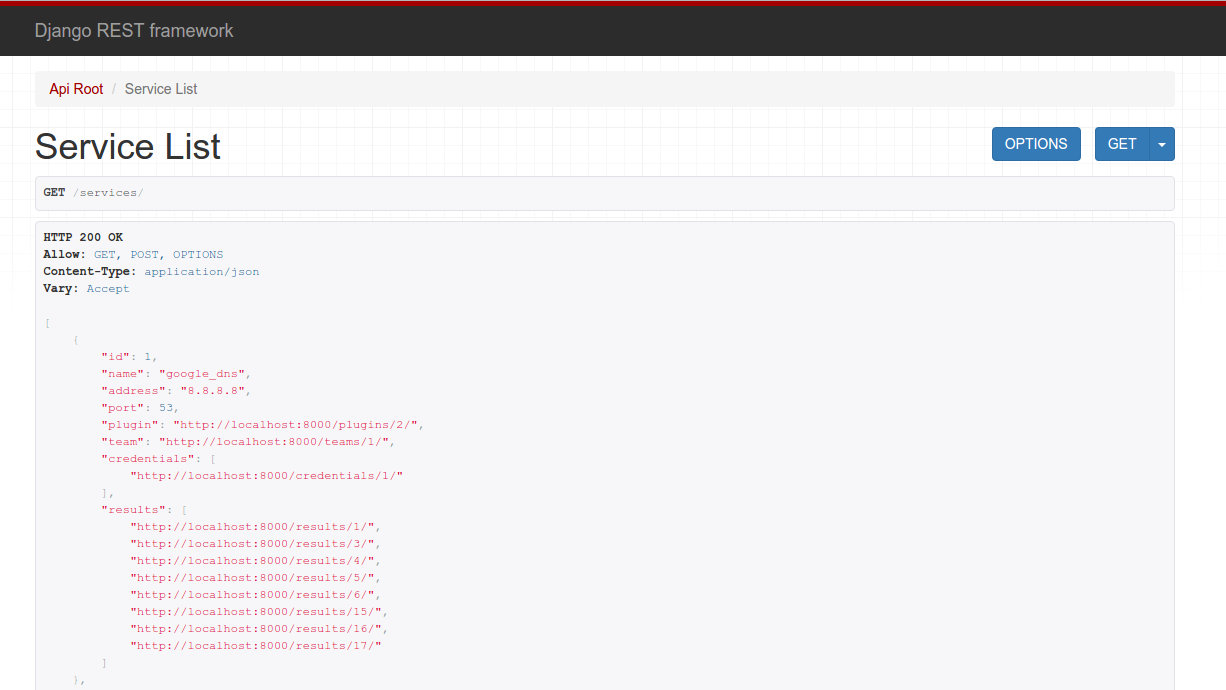
Finally, the entire application runs in a collection of Docker containers. I’m using Docker Compose to make container management even easier. The only dependencies for the entire project are docker and docker-compose, the containers build and install all of their own dependencies so the scoring engine can be brought up in a couple of minutes with:
docker-compose build
docker-compose up -dDocker Compose also has a nice scale feature that lets you quickly deploy
duplicate instances of a given container. Scaling the number of workers is as
simple as:
docker-compose scale worker=20And everything just works - Docker Compose takes care of networking for us, Celery knows how to handle newly registered workers and workers that have disconnected, and it’s all controllable via the Django web UI.
It’s worth noting that this Docker/Celery/Django idea isn’t original - it’s actually a pretty well established framework for building distributed applications with web front ends. If you’re interested in reading more about this kind of project or how to build your own this is a pretty good guide to get started.
Conclusions and Future Development
I’m only a couple hours into development but we’ve already got the foundations of a (hopefully) much improved CCDC scoring engine. Looking back at our goals, we’ve already got a couple completed.
-
Scalability - use asynchronous workers to run scoring modules and be able to easily increase/decrease the number of workers. - Stability - keep it simple, stupid, and validate everything.
- Team Control - teams should be able to control scoring engine relevant data without requesting changes from the White Team.
-
Flexible Plugin System - new scoring modules should be easy to write and add. - Feature Pairity - with previous implementations. This means an intuitive user interface, admin control, inject administration and submission, etc.
The project, as it develops, will be available publicly under the NUCCDC github organization and I’m definitely interested in any feedback/contributions the CCDC community may have. If you’ve got ideas, open a pull request, or get in touch with me on twitter. There’s lots to do and I’d love to have some additional contributors.