Spontaneous Reload Cache
In microprocessor design, specifically the design of memory systems, there’s often a trade-off between performance and cost. Any second year computer scientist or computer engineer can tell you about the memory hierarchy and how faster but smaller memory systems effectively act as a cache for larger, cheaper, but slower storage. One big area of research in computer architecture is cache eviction policies - how the cache decides what to replace when it is full and an uncached object is requested. In my computer architecture class, I took a look at a novel last level cache (LLC) algorithm and put it to the test under realistic workloads. The results weren’t quite what I expected.
There are only two hard things in Computer Science: cache invalidation and naming things.
Cache Review
Most people reading this are probably familiar with the traditional model of the memory hierarchy - lower on the pyramid is slower, cheaper, and farther away from the processor and higher is faster, more expensive, and generally closer to the processor. Data (or instructions) that are used frequently tend to be resident in higher levels of the hierarchy resulting in cache hits, ideally, and if the processor requests something that a layer doesn’t have, it has to pay the cost of contacting the next level down the hierarchy - a cache miss. Once the request is fulfilled by the lower layer, the higher layers will store it so that if it’s needed in the future, the CPU can get to it faster.
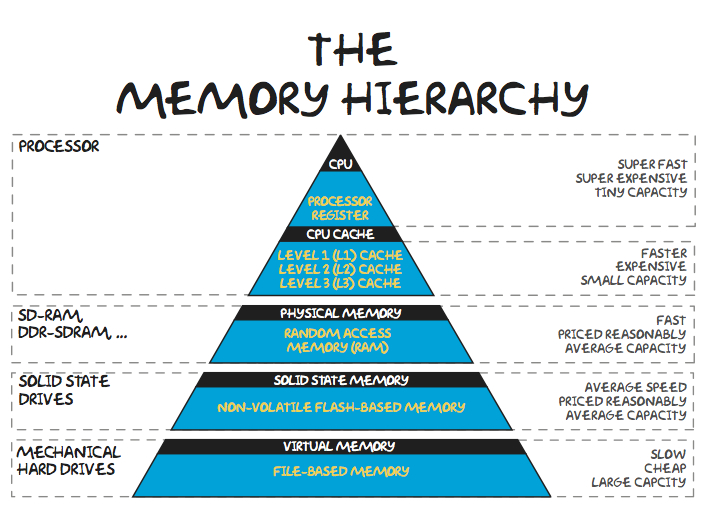
This is all fine and provides a lot of advantages in terms of both performance and cost. The difficult part of this process is how the higher level caches decide what to replace when they store something provided by a lower level cache. Since they’re of a finite size, it only makes sense that something has to go to make room for the requested data. Deciding exactly what to remove, or evict, is a popular area of research with no generally accepted answer. Modern processors today often rely on some form of least recently used (LRU) or pseudo LRU eviction.
Spontaneous Reloads
For my final project in Computer Architecture, I was tasked with researching a new or proposed architectural feature, implementing it in a simulator, benchmarking its performance, and then writing a report about my findings. I chose a paper out of the 2013 IEEE Networking Architecture and Storage conference entitled Spontaneous Reload Cache: Mimicking a Larger Cache with Minimal Hardware Requirement. In the paper, Zhang et. al. propose a cache eviction strategy that takes an active role in cache maintenance - in addition to evicting data from the cache on a cache miss after fetching the data from a lower level cache, an SR cache may evict and replace cache data on a cache hit, when the cache determines non-resident data is likely to be used again potentially hiding the latency of the lower level cache access.
Zhang et. al. accomplish this by introducing a metric they call Reuse Distance:
-
Idle Count – The number of cache accesses since a given block was last accessed
-
Reuse Interval – The interval, in cache accesses, at which this cache block is reused.
-
Reuse Distance = Reuse Interval - Idle Count
Sounds great, right? A cache that knows what data the CPU will need next and fetches it before the CPU asks might provide a huge improvement over a conventional cache. Unfortunately, keeping track of the Idle Count and Reuse Interval for all blocks of memory is utterly infeasible so data is instead only maintained for some subset of the blocks of memory called virtual blocks.
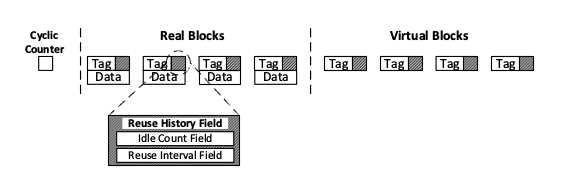
Then, on every cache access (hit or miss), if a virtual block’s reuse distance is less than that of a real block, the virtual block is spontaneously reloaded. Zhang et. al. argue that, effectively, the SR cache is able to increase its size by storing the Idle Count and Reuse Interval for more blocks of memory than a traditional cache would be able to hold given the same hardware resources.
Implementation and Testing
I implemented Zhang et. al.’s SR cache in SimpleScalar - a parameterized computer architectural simulator and ran it against a selection of benchmarks from various SPEC CPU 2006 workloads to measure cache performance. Using SimpleScalar’s sim-cache module, I measured the cache miss rate for caches of various sizes and configurations to compare SR against LRU as a baseline.
The results perplexed me - my SR cache implementation performed worse or as well as the LRU cache in nearly every benchmark. It wasn’t until I took a closer look at Zhang et. al.’s results that I realized their performance numbers were actually just as bad for a pure SR cache. In fact, they were only able to achieve modest improvements over LRU when they implemented what they called a hybrid SR cache - a cache that evaluates the performance of both an SR cache and a LRU cache in real time and selects the better performing cache to use.
Conclusions
An SR cache, while an interesting notion and a good exercise in learning about computer architecture, provides little to no performance improvement over LRU in most cases. The rare cases of improved performance in a hybrid setup with LRU explain the minor performance increase shown by Zhang et. al. Additionally, the concept of an SR cache is also more easily implemented in a simulator than in real hardware. Realistically, the potential of spontaneously reloading a cache block at any time would draw excessive amounts of power for minimal performance gain.
A more detailed discussion of the performance of an SR cache along with my implementation and full experimental results are available in my full report © Alex Interrante-Grant, 2016.